4 Experts on the Future of London Tech
London has established itself as a global tech powerhouse. How will the city make the most of this movement to ensure prosperity for businesses and talent?

In previous posts, we have discussed how to build a data science roadmap and determine which data you will use to help a newly hired data scientist hit the ground running. But it is not enough to have good ideas, data, and a data scientist: the data scientist needs powerful tools to do their job effectively. In this post we will discuss the types of tools required for a typical data scientist to be successful.
Modern technology products can generate a lot of data: clickstreams, telemetry, user-generated content like comments or reviews, and customer experience touchpoints, to name a few. It’s critical for this data to be located, mapped out, and if possible, loaded into a single central location. This central data store is the Data Layer of your Data Science operation.
If the majority of your data exists in relational databases (or what are often called SQL databases), then one of the easiest and best things you can do for your prospective Data Scientist is to build a Data Warehouse.
Data is not typically collected for the express purpose of “doing data science”; for example, an e-commerce site collects customer reviews in a database so that the reviews can be displayed on a page, not so that Data Scientists can perform natural language processing to discover patterns in the reviews. This means that, although the reviews are collected, they are difficult and time-consuming to analyze.
A data warehouse is an SQL database that contains all of the data necessary for analytics and business intelligence in your organization. If architected correctly, data warehouses are quick to query, easy to scale, and will contain all of the data that your Data Scientist needs to meet your objectives. Having this built before bringing in a Data Scientist will reduce time wasted on waiting for access to data or querying slow databases.
All the major cloud providers provide some type of data warehouse technology, which is easy to set up and scale. Amazon Web Services (AWS) provides Amazon Redshift and Redshift Spectrum, Google has Google BigQuery, and Microsoft offers Azure SQL Data Warehouse.
Data warehouses are powerful and useful as long as your data can be loaded into an SQL database. However, this is not always practical. Many modern tech organizations deal with data that is semi-structured or unstructured, in which case it can be quite challenging to load into a data warehouse, which is inherently built for structured data. In this case we might prefer to start with a Data Lake. A data lake is an organized data store that contains all of the data generated by your organization, usually in a raw format.
To effectively utilize a data lake, you will require tools to perform large scale queries and analysis on the data contained in the data lake. Querying tools are part and parcel of a data warehouse, but you’ll need to choose a querying tool to pair with your data lake. Traditionally, this has been done with a framework called Apache Hadoop, a set of software tools for performing scheduled or batch computations on enormous sets of data.
Another common tool for querying data lakes is Apache Spark, which allows Data Scientists to work interactively with big data sets using their preferred programming language (python or R). To better understand how data lakes work, check out this infographic created by G2 Crowd Learning Hub.
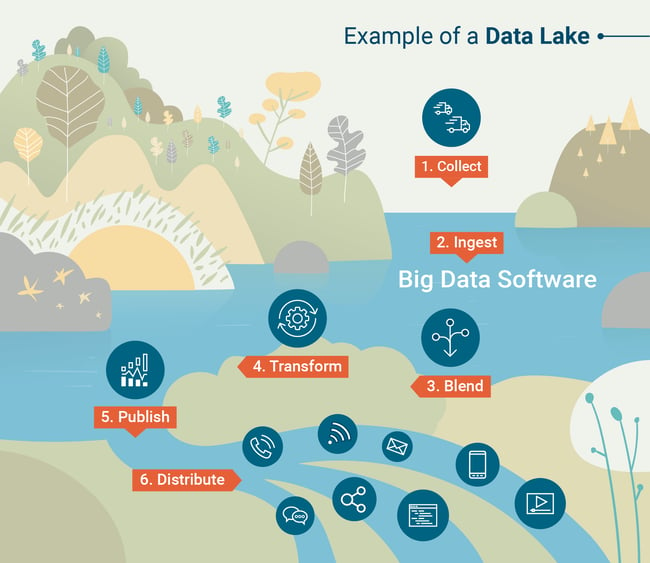
Source: G2 Crowd
Data Scientists do different things at different organizations, but one constant is that they will need to perform some pretty heavy number crunching. To do this, a data scientist requires a powerful laptop, and depending on the functions they will perform, they may need additional computation tools. The tools made available for computation form the compute layer of your data science operation.
Your Data Scientist’s productivity can be greatly improved by providing equipment with a large amount of computing power. Typical tools for data analysis are R or Python with Jupyter notebook, and these tools depend on storing datasets and performing computations in memory. This makes it common for a Data Scientist to max out their laptop’s memory, resulting in slow or even lost work. To combat this problem, choose the most RAM possible when purchasing a laptop for your data scientist.
Modern machine learning techniques are astonishingly good at doing things like recognizing images or faces, natural language processing, and many more tasks that were almost unimaginable for a computer even a few years ago. But these advances come at a cost: building machine learning models requires immense computational power—more than can be found in most laptops.
One important advancement is the development of GPU (Graphics Processing Unit) computing for machine learning. GPUs were originally designed as tools for efficiently rendering complex graphics, freeing up the CPU (Central Processing Unit) to do other things. While a CPU is designed to perform complex tasks one at a time, GPUs are designed to perform very simple tasks thousands at a time. This style of computation is perfect for the mathematics that deep learning and other complex machine learning methods use. Machine learning researchers and developers have learnt to harness GPU computing to accelerate the process of building these models.
To take advantage of GPU computing, you need access to a computer with a discrete GPU. Traditionally this would be found in gaming computers, but as GPU computing has gained popularity, discrete GPUs have become more widely available on high-end professional computers.
For most organizations, there are a lot of advantages to actually keeping all the machine learning work on the cloud. Services like Google Cloud Platform, Amazon Web Services, Microsoft Azure, and others allow users to rent a virtual instance of a well-equipped computer located in one of their data centres. The cloud instances can be accessed securely from any computer connected to the Internet, meaning that this approach does not require your Data Scientist to have a specialized laptop. There are a few other major advantages of cloud computing.
The most obvious advantage is scalability. If you need more computing power for a new project, additional resources can be marshalled instantly by increasing your monthly payment to the cloud service. And resources can be scaled back down just as fast. You may even choose to run multiple instances: a lower powered instance for day-to-day computing, and a higher powered instance that is only turned on for heavy lifting. This is common especially when GPU computing is required, as GPU-enabled instances tend to be more expensive.
Another advantage is data security. It’s not the best idea to download data to your personal laptop for analysis, especially if that data is sensitive. Using the same cloud provider for storage and computation is one way to keep your data more secure.
It is unfortunately too common that organizations will hire a data scientist but fail to provide them with the tools and equipment necessary to be successful.
Be prepared to listen to your new Data Scientist. This is especially true if you are hiring a seasoned Data Scientist with experience doing this type of work at scale at other companies. If you’re not sure what tools you’ll need to empower the Data Scientist, be prepared to collaborate with him or her on a Data Science roadmap that includes ideas, data, and computational resources.
Get the latest on upcoming courses, programs, events, and more — straight to your inbox.

You have been added to our mailing list, and will now receive updates from BrainStation.
London has established itself as a global tech powerhouse. How will the city make the most of this movement to ensure prosperity for businesses and talent?
Learn more about BrainStation's Intro Day, a popular event series that gives aspiring students a chance to try our coding bootcamps for a day while connecting with bootcamp alumni and hiring partners.
Protect your assets with our Cybersecurity course, designed to provide a detailed understanding of the threat landscape, and how to secure mission-critical data.